Set maximum response tokens in GPT for Docs
Set a cut-off limit for your responses (measured in tokens) in GPT for Docs. If the reponse is larger than this limit, it will be truncated. Helps control cost and speed.
| Term | Definition |
|---|---|
| Token | Tokens can be thought of as pieces of words. During processing, the language model breaks down both the input (prompt) and the output (completion) texts into smaller units called tokens. Tokens generally correspond to ~4 characters of common English text. So 100 tokens are approximately worth 75 words. Learn more with our token guide. |
| Token limit | Token limit is the maximum total number of tokens that can be used in both the input (prompt) and the response (completion) when interacting with a language model. |
-
In the GPT for Docs sidebar, click Model settings.
-
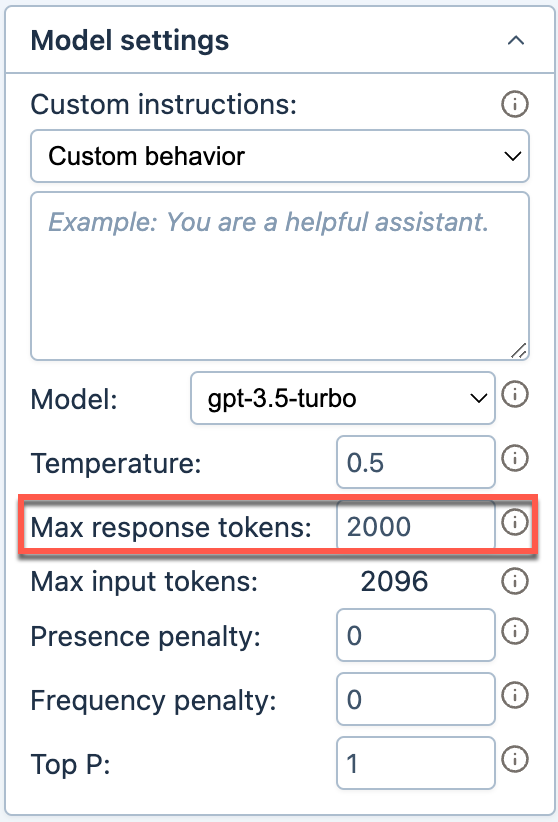
Enter a value for Max response tokens.
Rule: max response tokens + input tokens ≤ token limit
This means that when you set Max response tokens, you must make sure there is enough space for your input. Your input includes your prompt, custom instructions, context, and elements sent by GPT for Docs with your input (about 100 extra tokens). You can use OpenAI’s official tokenizer to estimate the number of tokens you need in your response.
You can now submit a prompt in the current document with the new maximum response size. Once a prompt is submitted, the maximum response size is saved along with all Model settings values, and is used for all prompts executed from Google documents.
What's next
Configure other settings to customize how the language model operates.