Configure GPT function behavior in Sheets
Configure model settings to customize how GPT functions behave in your spreadsheet.
When cache is enabled, existing GPT formulas will not automatically update to new model settings when you re-run the formulas.
To re-run an existing formula with the new settings:
-
Change a parameter in the formula and press Enter.
-
Disable the cache, select the formula, and regenerate its results.
Add global instructions
Provide global instructions to specify preferences or requirements that you'd like the AI to consider when generating responses. The instructions apply to all GPT functions in the current spreadsheet.
-
In the sidebar, select GPT functions.
-
Expand Model settings.
-
In the Global instructions section, select the type of instructions you'd like to add and edit them if needed.
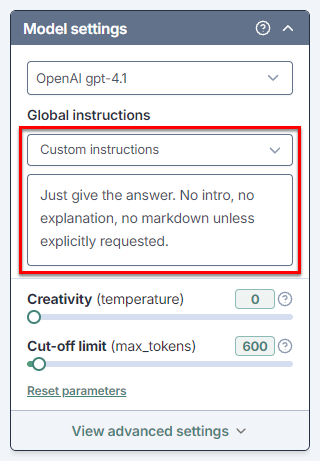
The AI takes the global instructions into account when generating responses for GPT functions in the current spreadsheet.
Set the creativity level
Control how creative the AI is by setting the creativity level (also called temperature). Lower creativity generates responses that are straightforward and predictable, while higher creativity generates responses that are more random and varied.
For more information about temperature as used by OpenAI to set the creativity level, see our temperature guide.
-
In the sidebar, select GPT functions.
-
Expand Model settings.
-
Use the slider to set Creativity between 0 and 1.
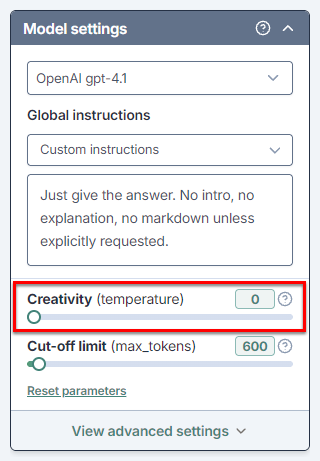
The AI uses the creativity level when generating responses for GPT functions in the current spreadsheet.
Adjust advanced settings
Adjust the advanced settings to have greater control over generated output for GPT functions in the current spreadsheet. For more information about the settings, see the OpenAI API documentation.
| Term | Definition |
|---|---|
Token | A token is a unit of text, such as a word, subword, punctuation mark, or symbol. Models split all input and output text into tokens for processing. Model providers use tokens as the basic unit for measuring model usage. The total number of tokens in a prompt (input) and the model's response (output) determines your credit consumption. For more information, see Tokens and How credits are consumed. |
Top P | Helps adjust creativity level – Lower values result in more focused output, while higher values allow for more creative responses. |
Frequency penalty (not available for all models) | Penalizes tokens based on their frequency in the text so far – Higher values discourage the model from repeating the same tokens too frequently, as the more they appear in the text, the more penalized they get. |
Presence penalty (not available for all models) | Penalizes new tokens based on whether they appear in the text so far – Higher values encourage the model to use new tokens that are not penalized. |
-
In the sidebar, select GPT functions.
-
Expand Model settings.
-
Expand View advanced settings.
-
Use the corresponding sliders to set the values for:
-
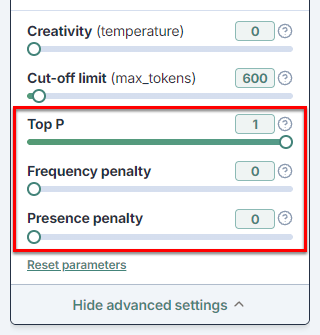
Top P: Adjust creativity by setting the value between 0 and 1.
Set the creativity level to 1 when the value for Top P is lower than 1.
-
Frequency penalty: Set a penalty between 0 and 2 to apply to tokens each time they are repeated in the result.
-
Presence penalty: Set a one-time penalty between 0 and 2 for tokens that appear more than once in the result.
-
GPT for Sheets uses the advanced settings to generate responses for GPT functions in the current spreadsheet (when a model supporting the settings is selected).
Set the cut-off limit
Set a cut-off limit for the responses of GPT functions in your spreadsheet to manage the size of the result in tokens. This won't shape the response, but if the response goes beyond this limit, it will be truncated.
| Term | Definition |
|---|---|
Token | A token is a unit of text, such as a word, subword, punctuation mark, or symbol. Models split all input and output text into tokens for processing. Model providers use tokens as the basic unit for measuring model usage. The total number of tokens in a prompt (input) and the model's response (output) determines your credit consumption. For more information, see Tokens and How credits are consumed. |
Context window | Total amount of tokens that the model can consider at one time, including input (prompt) and output (result). The context window size depends on the model used. |
Max output | Maximum number of tokens that can be generated in the output by a given model. Max output is typically much lower than Context window. |
Cut-off limit | Maximum size of the result in GPT for Sheets, measured in tokens. If the result is larger than this limit, it will be truncated. Helps control cost and speed. Cut-off limit is set 200 tokens below Max output. |
-
In the sidebar, select GPT functions.
-
Expand Model settings.
-
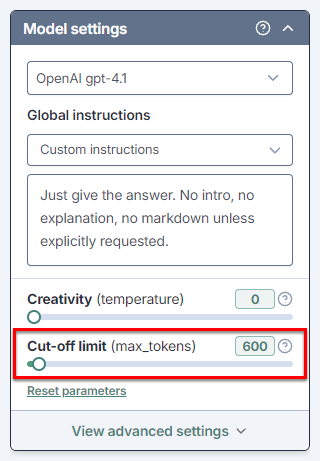
Set Cut-off limit as follows:
-
If you expect short responses, lower the limit to get faster responses.
-
If you expect long responses, increase the limit to make sure they are not truncated.
-
If your response is truncated, increase the limit.
-
GPT for Sheets now applies the cut-off limit to all GPT formula results.
What's next
-
Select the model that best fits your needs.